Long Term Archive User Manual
This is a short manual on how to search for and retrieve data from the LOFAR Long Term Archive (LTA).
To access the LTA, go to: lta.lofar.eu
In case of problems, please refer to the Frequently Asked Questions section below.
Almost all of recorded and (pre-)processed LOFAR data is made available to users through the Long Term Archive (LTA).
The LTA has 3 different tape storage sites located in Amsterdam (NL), Juelich (DE) and Poznan (PL), where all the (accepted and validated) archived LOFAR data products are stored.
All the data stored on these sites adhere to the LOFAR Data Policy, where the LOFAR metadata is publicly available, and data will typically remain propriety for a period of 1 year. After this one year it can be staged and downloaded by users with a valid LTA account.
Here, we explain how to gain access to the LTA, how to navigate it, and how to download your desired data.
User access
Please refer to the LOFAR user access page, for an overview of the authentication / authorization procedures associated with LOFAR.
Account privileges
The LTA catalogue can be searched directly without needing an account. Access to all projects and search queries will return results of the entire catalogue because metadata are public for all LTA content.
Staging and subsequent downloading of public data always requires an account with LTA user access privileges. Users that are a member of a submitted LOFAR proposal can use the associated account for accessing the LTA. If you do not have an account yet, please submit an account creation ticket to the SDCO helpdesk as explained above.
To stage and retrieve project-related data in the LTA which are proprietary, you need to have a LOFAR account that is enabled for the archive and coupled with the projects of interest. In case your account should be coupled with a project and currently is not, you can request the SDCO to add you to the list of co-authors of the project. When you send such a request, you must add the project's PI in cc, or let them make the request for you. After SDCO adds you to the project, you might get an email asking you to set a new password in ASTRON Web Applications Password Self Service.
Please read the LOFAR Data Policy for more information about proprietary vs public data.
Navigating the website
The LTA header menu, as shown below, gives access to the main functionalities.

Users can log into the LTA through the LOGIN button at the top right.
The HOME tab is the homepage of the website, where often important announcements are displayed such as system outages and other issues.
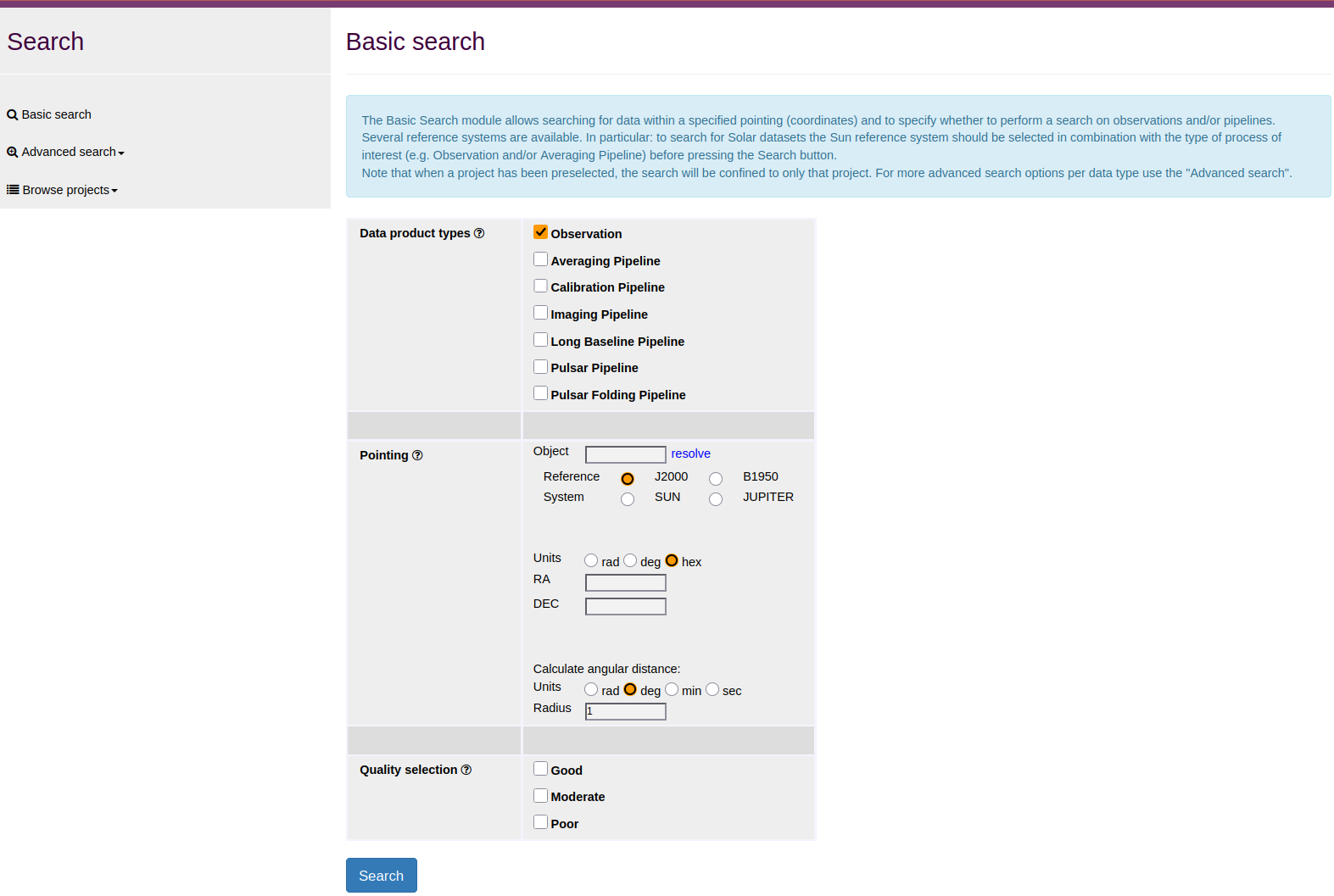
The SEARCH DATA tab is the place to start a generic data search. Clicking this tab will, by default, show the basic search page, where users can select the data product type of interest and perform a cone search. Other search options are also made available on the left-hand side of the page (shown below).
The BROWSE PROJECTS tab is particularly useful for project related searches, as well as for checking either public projects or user's co-author membership. At this stage, several actions are allowed.
A more detailed overview of each of the possible options on the search/browse pages follows below.
Lastly, the HELP tab opens a page with some FAQs and other useful information.
Searching for data
As listed above, there are several different tabs to search for data. This section will elaborate on the use of each search option to query data, including some special methods
Basic search
The Basic Search module allows searching for data within a specified pointing (coordinates) and specifying whether to perform a search on observations and/or pipelines. This is particularly useful if you want to perform a cone search, or find all data on a particular pointing.
Several reference systems are available. In particular: to search for Solar datasets the Sun reference system should be selected in combination with the type of process of interest (e.g. Observation and/or Averaging Pipeline) before pressing the Search button. Note that when a project has been preselected, the search will be confined to only that project.
- Log in to https://lta.lofar.eu/.
- Click SEARCH DATA in the top menu.
- Specify the data product types of interest and a target name or coordinates.
- Click on “Search” button at the bottom.
- From the screen that follows, you should be able to view and stage the data products by selecting the desired data through the check marks and clicking 'Stage selected'.
Advanced search
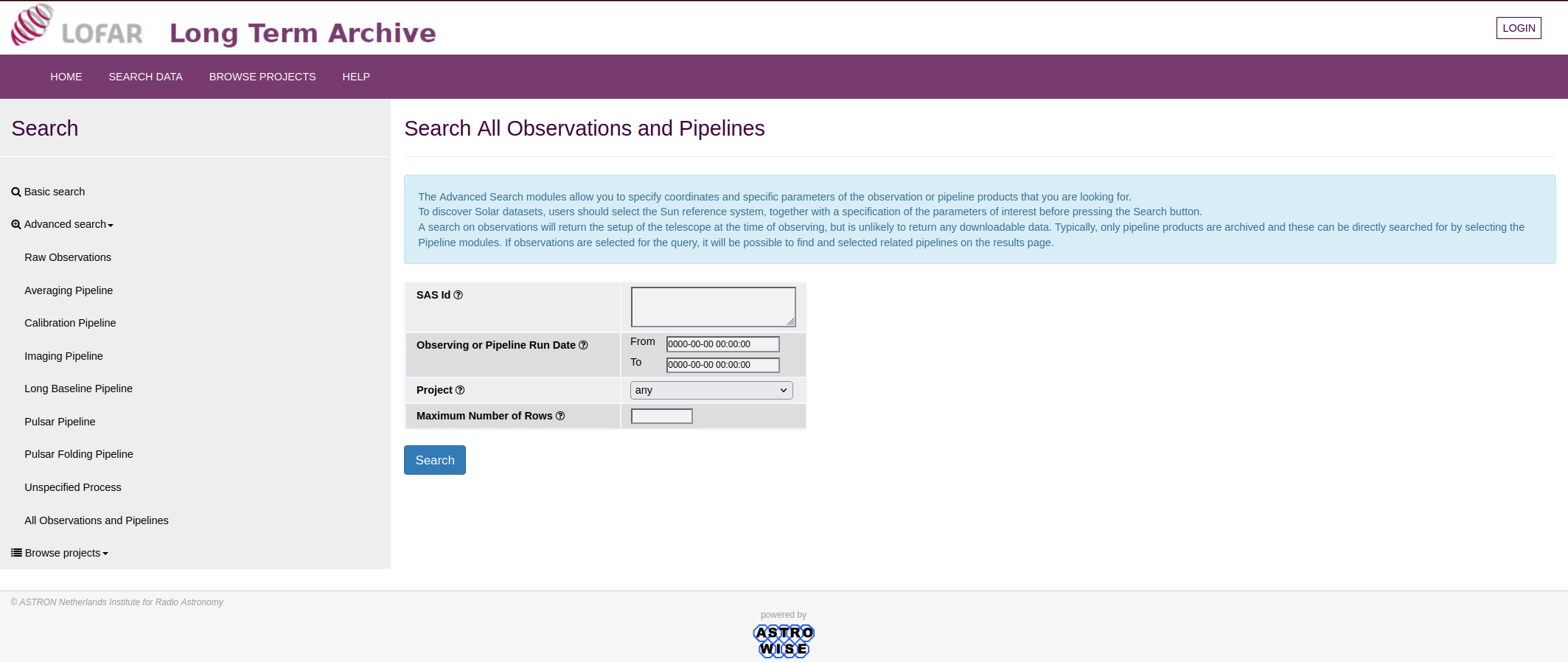
The Advanced Search modules allow for a more advanced search with different parameters for each of the different data types on the LTA, including specification of coordinates, resolutions and unspecified data. This search mode (especially in the All Observations and Pipelines tab) is incredibly useful if you know the SAS IDs of the data you are searching for to quickly access them.
To discover Solar datasets, users should select the Sun reference system, together with a specification of the parameters of interest before pressing the Search button.
A search of raw data will return the metadata, but may not always return downloadable data. Typically, only pipeline products are archived and these can be directly searched for by selecting the Pipeline modules. If the raw observation is selected for the query, it will be possible to find and select related pipelines on the results page by staging the observation data and then selecting the pipeline products.
- log in to https://lta.lofar.eu/.
- click SEARCH DATA in the top menu.
- click on the side panel Advanced Search drop-down list.
- specify the data product types of interest from the drop down list.
- select products features and specify a target name, coordinates or SAS ID (unique identifier for a given observation/pipeline run).
- click on the “Search” button at the bottom.
- from the screen that follows, you should be able to stage the data products by selecting the desired data through the check marks and clicking 'Stage selected' and 'Submit'.
Project search (to restrict all data searches to that project only)
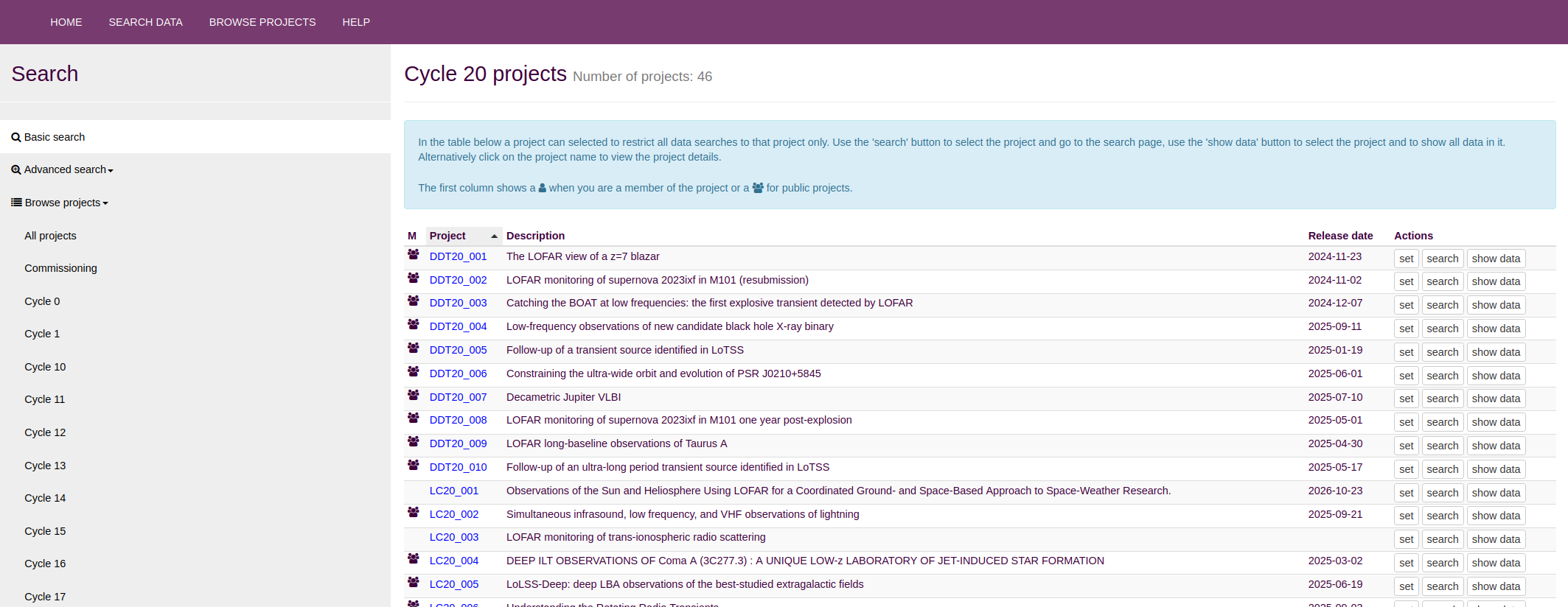
Under the Project Search menu is a table showing projects that can be selected to restrict all next data searches to that project only. Use the “Search” button to select the project and be directed to the Basic Search page per selected project. This will still perform a cone search, but restricted to data to the selected project. Use the "Show data" button to select the project and be directed to a page where you can select to see all data of a particular data type. This can be particularly useful if you want to inspect all data in a project. Alternatively, click on the project name to view the project details. The first column shows if you are a member of the project or if the project is public.
- log in to https://lta.lofar.eu/.
- click BROWSE PROJECTS in the top menu.
- Select which cycle the project is part of.
- Actions in this menu include:
- Clicking on the project name to view the project details and eventually select it.
- Using the "Search" button to select the project and go to the search page. Subsequent searches will then be done within that project.
- Using the "Show data" button to select the project and to show all data in it.
- from the screen(s) that follow(s), you should be able to either search / select / stage the data products.
Special search tricks
There are some useful ways to find your data in the LTA that allow for easy selecting and navigation of your data. This section will elaborate a few more advanced options for browsing the LTA.
Queries
While using the Advanced Search tab, you can select a range of SAS IDs by using colons. For example if you want all observations and pipelines that have SAS ID in the range of 432000 to 432190, you can supply it as: 432000:432190 in the search box. Similarly you can insert a comma separated query for a (nonsuccessive) list of SAS IDs. Note that you can query only up to a 100 items at a time.
DBView
For advanced use cases, a service is available at https://lta-dbview.lofar.eu/ that gives the option to run your own queries on the database or build them using a tables view. General help on usage is accessible from the service page.
A potentially useful query is shown below, that gives you all files for a certain SAS ID.
SELECT fo.URI, dp."dataProductType", dp."dataProductIdentifier",
dp."processIdentifier"
FROM AWOPER."DataProduct+" dp,
AWOPER.FileObject fo,
AWOPER."Process+" pr
WHERE dp."processIdentifier" = pr."processIdentifier"
AND pr."observationId" = '123456'
AND fo.data_object = dp."object_id"
AND dp."isValid"> 0
Here, '123456' should be replaced with the SAS ID of an Observation/Pipeline you are looking for. Even though this is a bit confusing, pipeline SAS IDs are stored under "observationId", just as for observations. To be able to run this query, you have to go to the link above, login as the right user, select the right project, and then put this query into the “Manual SQL”.
Example: You can also modify these queries. Available tables and fields can be inspected by following the "Tables" link at the top of the DBView page. For example if you want to also know the MD5 checksum, you can run:
SELECT fo.URI, fo.hash_md5, dp."dataProductType", dp."dataProductIdentifier",
dp."processIdentifier"
FROM AWOPER."DataProduct+" dp,
AWOPER.FileObject fo,
AWOPER."Process+" pr
WHERE dp."processIdentifier" = pr."processIdentifier"
AND pr."observationId" = '123456'
AND fo.data_object = dp."object_id"
AND dp."isValid"> 0
Viewing data
Once you have performed your cone search, displayed all your data in your project, or retrieved the list of SAS IDs you want to search for, you will be taken to the data overview menu, where there are again several options on how to display and explore the data you searched for.
Depending on what search you performed, you will be shown a page with (several) dropdown menu(s), which can include: Observation, Averaging Pipeline, Calibration Pipeline, Imaging Pipeline, Long Baseline Pipeline, Pulsar Pipeline, and Unspecified.
- Observation
The observation tab holds all the raw observation (meta)data. The default columns that are displayed for observation data are: Project name, Release date, SAS ID, Antenna Set, Instrument Filter, Channel Width, Number of Subarray Pointings (with hyperlink to display table to show the different SAP details), Number of core stations, Number of remote stations, Number of international stations, (total) Number of stations (with hyperlink to display table that lists all station names in the data), Number of correlated data products (interferometric data specific), Number of beam formed data products (time-domain specific), and quality flag (as determined by SDCO).
- Averaging Pipeline
The averaging pipeline tab holds all interferometric data that have been processed with the pre-processing pipeline, which contains time/frequency averaging steps, Dysco compression steps, and initial demixing of close offending sources (of which most notably are the A-team sources). More detailed information on the pre-processing pipeline can be found in its documentation pages. The default columns that are displayed for observation data are: Project name, Release date, Pipeline name (which often is named as pointing_name_pipeline_initials), Pipeline version, SAS ID, Frequency integration step, Time integration step, strategy name, Flag autocorrelations (1=True, 0=False), Demixing (1=True, 0=False), Number of correlated data products (with hyperlink to list of all sub-bands/measurement sets), Source data product (with hyperlink to observation (meta)data that the pipeline processed on), All data products (showing all of the different kinds of data products available), and Quality flag (as determined by by the automated processing pipelines run by the ASTRON Science Data Center).
Most of the recorded interferometric data will be processed with the pre-processing pipeline due to it significantly shrinking the data size compared to raw data. The exact parameters of the pipeline will be determined at the time of proposing, and can be found back in the aforementioned columns.
- Pulsar Pipeline
The pulsar pipeline tab hold all time-domain/beamformed data that have been processed with the PuLP pipeline. More detailed information on Pulp can be found in its documentation pages. The default columns that are displayed for pulsar pipeline data are: Project name, Release Date, Pipeline name (which often is named as pointing_name_PULP), Pipeline version, SAS ID, Pulsar Detection, doSinglePulseAnalysis, Strategy name, convertRawto8bit, Sub-integration length, Skip RFI Excision, Skip Data Folding, Skip Optimize Pulsar Profile, Skip Convert Raw Into Folded PSR FITS, Run Rotational Radio Transient Analysis, Skip Dynamic Spectrum, Skip Pre-fold, Source Data Product (with hyperlink to observation (meta)data that the pipeline processed on), All Data Products (with hyperlink to list of all data products, incl. coherent and incoherent stokes files and PuLP summary files), Quality flag, and Pulsars. Ancillary information for the content of (some of) the columns is provided by a tooltip appearing when the user hovers the mouse pointer on the column title.
The exact parameters of the pipeline will be determined at the time of proposing, and can be found back in the aforementioned columns.
- Unspecified Process
The unspecified processes tab hosts all the data whose metadata have become lost/corrupted. These data are still registered to a particular project and contain a SAS ID number, but the data type and other data properties are unknown. The default columns that are displayed for unspecified process data are: Project name, Release date, SAS ID, Observing mode (which is often marked Unknown), Process Description (which is often "Unknown process, information generated by Ingest"), and Number of Unspecified Data Products (with hyperlink to list of all unspecified data products (file names) under that SAS ID. Note that the data itself is not corrupted, only the metadata that is being displayed in the LTA, so if you are searching for a SAS ID and (for example) one sub-band lands in the unspecified tab, then you can stage this sub-band separately and combine it with the observation/pipeline data and process the data whole.
Tab navigation buttons
Underneath each of the above described tabs there are several different ways to select, explore and eventually stage data.
Below each of the headers you can find 4 buttons: Edit Columns, Stage Selected, Show Data Products, Show Pipelines.
- Edit Columns
The Edit Columns button spawns a pop-up window that allows the user to (de)select columns that will be displayed for that specific tab. Note that this will refresh the search page, so you might need to re-submit the SAS ID/project/object you searched for. Your selection of columns to be displayed will be saved in your browser session, so the next searches will display those columns again. Also note that when trying to display all columns, that the webpage will overflow, so we recommend only opening the columns that are really necessary to maintain a nice overview.
- Stage Selected
The Stage Selected button allows for a quick way to stage all data (at SAS ID level) that are selected through the tick boxes present on the very left-hand-side of the rows within a tab. This button might reveal different views once clicked depending on which tab you have selected the data from. If you selected tick boxes in the Observation tab, you will be redirected to a new page where you can select to stage the Observation data or the Pipeline data (if it exists). Usually if data has been processed with the pipelines, then that is usually the only data that is stage-able, and the observation tab holds only the metadata. Either way, depending on what data you wish to stage, you can press the STAGE button on the left-side of each row to stage that desired data product.
- Show Data Products
The Show Data Products button allows for a quick way to show all data for any selected SAS ID that was selected using the tick boxes per tab. Depending from which tab you select the SAS ID and press the Show Data Products button, you might encounter an additional page. If you select Show Data Products on the Observations tab, it will take you to a page where it asks you which data (observation or pipeline (if it exists)) you want to display in detail, and under the Pipelines tabs it will show the pipeline data. In any of the data type cases, it should show a page where each file (corresponding to a subband) and its full metadata is displayed. From that page the data can also be staged in case you want to select specific subbands for download.
- Show Pipelines
The Show Pipelines button only works when ticking boxes for SAS IDs under the Observations tab, and it allows for quickly finding what processing has been done on particular observation data. Once this button is selected, it will open a new sub-search and shows all existing metadata on pipeline processes based on the selected observation. From here the above explorations can be performed again.
Tips
Note that observations often have no raw data in the archive, but the metadata is visible because subsequent pipelines have processed the raw data further which are then ingested into the LTA. To get to the pipelines related to observations, use “Show Pipelines”.
To see whether observations or pipelines have data products in the LTA, look for the “Number of Correlated/BeamFormed Data Products” column. These columns, as well as a few others, can also be used to navigate to the relevant data products.
Staging data
As described above, there are many different ways to view and select data. Ultimately, in order to download data from the LTA we need to select them for staging.
The LOFAR Archive stores data on magnetic tape. This means that it cannot be downloaded right away; it has to be copied from tape to disk first. This process is called 'staging'.
Once you selected all the data you want to stage, you can press the Stage Selected to be shown a list of file names that you have selected for download. This shows you the following message shown below, where it tells you the size per file, and the total size of all files together. After pressing submit you will be forwarded to your StageIT request where you can see the request ID and manage the staging request. Once a request ID is made, it means that a request has been sent to the LTA staging service to start retrieving the requested files from the tape and make them available on disk. You will get a confirmation e-mail, to acknowledge that your staging request was received and the process was queued. When the files are staged, you will get a notification email informing you that your data are ready for retrieval.
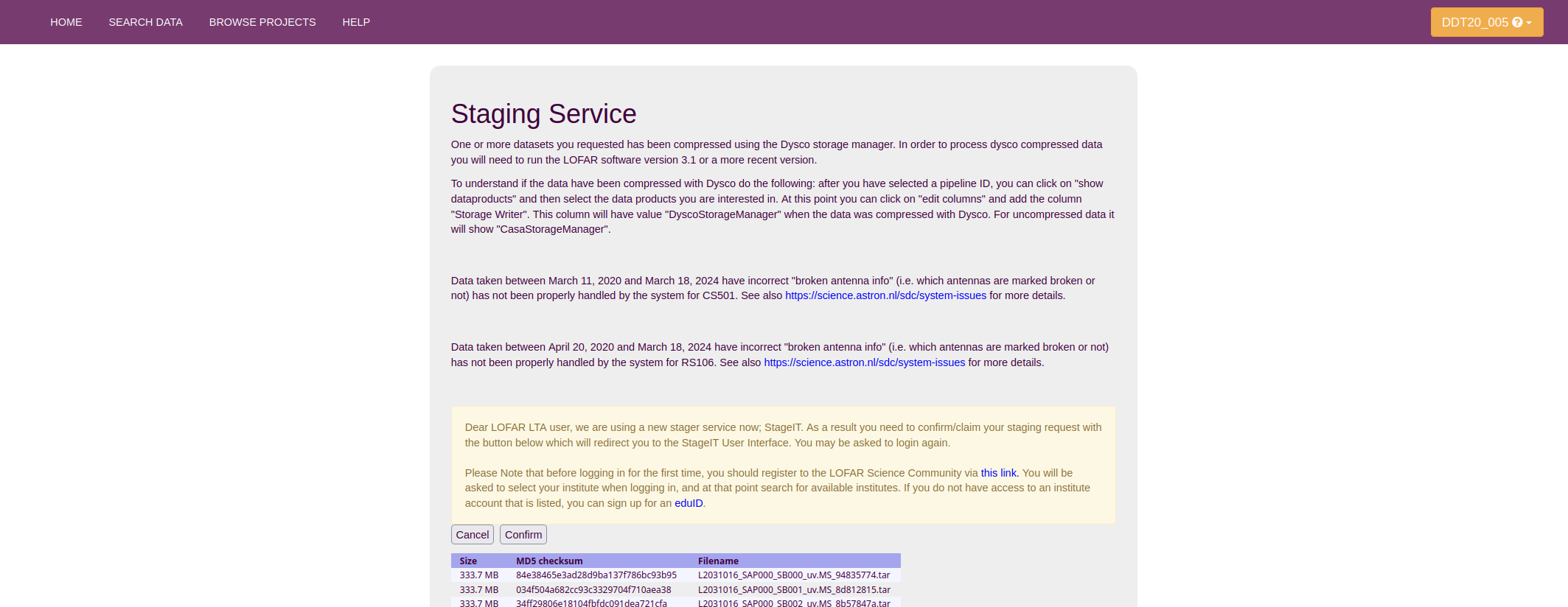
The e-mail that you get when the staging on disk is complete gives you a two files: macaroon.txt and webdav.txt
Beware
- Unless you have an extremely fast connection (10 Gbit/s or more), it is in general advisable to stage no more than 15 TB at a time (see also point 4). At maximum efficiency a 1 Gbit/s connection will already take 12 hours to retrieve 5 TB of data, in practice it will often take quite a bit more.
- On a 1 Gbit/s connection as a general rule of thumb, you should be able to retrieve data at about 100-500 GB/hour, especially if you try to retrieve 4-8 files concurrently. If you see speeds much lower than this, you might have some kind of network problem and should in general contact your IT staff.
- Staging the data from tape to disk might take quite a bit of time. In the large data centres that the LTA uses, the tape drives are shared with all users and requests are queued. This is not just for users of LOFAR, but also for users associated with other projects that have their data stored in the data centers. This might mean that it takes anywhere from a few hours to days to stage a copy of your data from tape to disk.
- The amount of space available for staging data is limited although quite large. This space is however shared between all LOFAR LTA users. This includes LTA operations for buffering data from CEP to the LTA before it gets moved to tape. If many users are staging data at the same time, and/or SDC operations is transferring large amounts of data, the system might temporarily run low on disk space. You might then get a message that your request was only partially successful. In general the request will still finish 1-2 days later and we do monitor if requests get stuck and restart if needed.
- We strive to keep a copy of data that was staged on disk for at least one week so you have some time to download it. After that it might get removed to make space for more recent requests. In accordance with the LOFAR data policies, the data will be available if you need to access it again at a later stage but you might need to stage a copy to disk again. The access authorization token provided by StageIT is valid for one week. If a user desires to access the data later, the request can be restarted in StageIT which will result in extension of the access period with one week.
- We are continuously trying to improve the reliability and speed of the available services. Please contact SDCO if you have any problems or suggestions for improvement.
- The data centres that the LTA uses also have maintenance or small outages sometimes. SDCO can advise you if this is the case and when it is planned to end if you are having trouble accessing data. In general, outages that affect user data access will be announced on the main page of the LOFAR LTA website and will not be at the same dates as the LOFAR stop days.
TBB data
TBB data is not registered in the LTA catalog yet. It needs to be staged manually. Please send a request at https://support.astron.nl/sdchelpdesk for the exact filenames. Then, create a stage request in StageIT using them,and download the data as described in the StageIT documentation.
Download data
You can download your requested data with the files attached to your e-mail notification. There are different possibilities and tools to do this. For all information about StageIT capabilities and download methods please refer to the StageIT documentation.
wget download
In order to download LOFAR data with wget according to the StageIT documentation we recommend you to configure your~/.wgetrc file.
Make sure that file access authorisations for the .wgetrc file only allow access by you (the owner). e.g.:
chmod 600 .wgetrc
You can include your staging macaroon to your .wgetrc file, but if you download several datasets at a time it is easier to create a separate config file and point to it in your wget command.
For more details on this, please check the `Working with wget' page in the StageIT documentation page.
There is no easy way to have wget rename the files as part of the command directly. You can use the following Python script (for example) to take care of renaming and untarring the downloaded files:
#!/usr/bin/env python
"""This script is a pipeline to untar raw MS. 1 input is needed: the working directory.
AUTHOR: J.B.R. OONK (ASTRON/LEIDEN UNIV. 2015) EDITED BY: M.IACOBELLI (ASTRON)"""import glob, os, sys
usage = 'Usage: %s inDIR' % sys.argv[0]
try:
path = sys.argv[1]
except:
print(usage) ; sys.exit(1)#path = "./" # FILE DIRECTORY
filelist = sorted(glob.glob(path+'*.tar'))
print('LIST:', filelist)#FILE STRING SEPARATORS
extn='.MS'
extt='.tar'#LOOP
print('##### STARTING THE LOOP #####')
for infile_orig in filelist:#GET FILE
infiletar = os.path.basename(infile_orig)
infile = infiletar
print('doing file: ', infile)spl3=infile.split(extn)[0]
newname = spl3+extn+exttinFILE = path+infile
newFILE = path+newname
# SPECIFY FILE MV COMMAND
command='mv ' + inFILE + ' ' +newFILE
print(command)# CARRY OUT FILENAME CHANGE !!!
# - COMMENT FOR TESTING OUTPUT
# - UNCOMMENT TO PERFORM FILE MV COMMAND
os.system(command)
os.system('tar -xvf '+newFILE)
os.system('rm -r '+newFILE)print('finished rename / untar / remove of: ', newFILE)
FAQ
Below is a collection of frequently asked questions, that include general questions together with some troubleshoot questions.
General
- Why is data retrieval so cumbersome?
- What is an appropriate amount of data to retrieve?
- What is all this staging stuff about?
- Do I have to make new requests via the web catalog?
- My download speeds are too slow. What can I do?
- I want to contact Science Data Centre Operations. What information should I include?
Why is data retrieval so cumbersome?
It is important to understand the data volumes of LOFAR are pretty huge and handling them requires different technologies than what we all know and use in our everyday life. For instance, LTA data is stored on magnetic tape and has to be copied to a hard drive (getting 'staged') before it can be retrieved. To transfer these amounts of data within reasonable time requires careful consideration and special tools and we try to make the LTA as convenient to use as possible.
What is an appropriate amount of data to retrieve?
This depends. As a rule of thumb, we ask you to keep your requests below 15 TB in volume. Specifically, there are essentially two things to consider: the capabilities of your own system and the capabilities of the LTA services.
The most important thing to know about LTA capabilities, is that the disk pool that temporarily holds your data and from where it can be downloaded, has a limited capacity. This means that the data you requested is only available for download for a limited time (since the space is needed for new requests at some point). Your data is only guaranteed to stay available for one week. It can be re-requested after that, but you should never request more data than you can download within a few days. In most cases this is limited by the capabilities of your own system, especially your network connection (and available local storage space, of course).
The second most important LTA limit is the number of files that can be processed at the same time. Some projects do not have a lot of data volume, but the data is distributed over very many files. With large file counts, the management of the request itself puts a large load on the system. There is a maximum queue size of 10,000 files for all user requests together. So make sure to only occupy a fraction of that and wait until earlier submitted requests have finished (you get notified) before you submit new requests.
Note that the larger your request, the longer it takes until you can retrieve the first file. Also, please limit the number of requests running in parallel to a few, especially when they contain many files. In principle, we avoid introducing hard limits, but rely on reasonable user behavior. This also means that you can block the system for a long time or, in the worst case, even bring it down. So please act responsibly or we might have to enforce some limits in the future to keep the system available for other users. Be aware, that we may cancel your request(s) in excessive cases to maintain LTA operation.
If you, by accident, staged some 100,000 files or 100 TB of data, you can "abort" your requests through StageIT.
What is all this staging stuff about?
These are technical terms that refer to the storage back-end of the LTA. Each of the three LTA sites (in Amsterdam, Juelich, and Poznan) operates an SRM (Storage Resource Management) system. Each SRM system consists of magnetic tape storage and hard disk storage. Both are addressed by a common file system, where each file has a specific locality: it can be either on disk ('online') or on tape ('nearline') or both. The usual case for LTA data is that it is on tape only. Since the tape is not directly accessible but only through an (automated) tape library, the data on it has to first be copied from tape to disk in order to retrieve it: staging. Only while the data is (also) on disk, you will be able to download it. To save cost, the disk pool is of limited capacity and only meant for temporary caching data that a user wants to access. After 7 days, all data is automatically 'released', which means that it may be deleted from the disk storage, as soon as the space is required for other data. It then has to be staged again in order to become accessible again, which can be done by pressing "restart" on on StageIT per request ID.
Usually, you don't have to worry about the details. But be aware, that data retrieval is a two-step procedure: 1) preparation for download ('staging') and 2) the download itself. Also, take care not to request too much data at the same time.
My download speeds are too slow. What can I do?
First of all, you have to check how slow your download really is. If 'wget' shows an estimated time of arrival of several hours, this does not necessarily mean that the download is 'slow': some files in the LTA are also just really huge. In most cases, your local network connection will be the bottleneck. For instance, a standard 'Fast Ethernet' network connection allows download speeds of around 120 MB/s at a maximum. Our systems are able to handle that, easily. In case you can rule out your network connection as the bottleneck: there are different ways to download your data and not all provide the same performance. Http downloads are the slowest option. The speed is limited by the server's network connection (~120 MB/s), which is shared by all users, and an upper limit per download (around ~30 MB/s) for technical reasons. If your download maxes out at the per-download limit, you may try to start up to four downloads in parallel. Note: There is no performance benefit to expect from more than four parallel transfers! However, there is a connection limit, which you may trigger if you start too many parallel downloads. Also, please refer to the relevant StageIT documentation on webDAV usage.
I want to contact Science Data Centre Operations. What information should I include?
You are welcome to contact Science Data Centre Operations in case of problems that you cannot solve yourself. However, we kindly ask you to include all important information in your inquiry, so that we can quickly help you with your problem without too much back and forth:
- It is absolutely essential, that you include a clear answer to the following:
- What exactly did you try to do?
- What went wrong?
- When exactly did it fail (so we can check the logs)?
- If you are asking about a command that failed, please copy-paste the exact command that you executed together with the full terminal output. Some tools have a '-debug' option, which provides additional information, e.g. about your environment. It helps a lot if you could use that option when you copy-paste your command output.
- If you are using some script somebody gave you, please note that we are no clairvoyants and have no idea what the script you're using actually does. We can most likely not understand what went wrong from the output of some random script. Please check this page carefully, whether the officially supported ways of data retrieval work for you. If they work, please ask the one who supplied you with the failing script, why their script fails. If the official ways don't work, please forget about your script for a moment and provide the output of the official tool that does not work for you.
Troubleshoot
- I did not receive a mail notification that my request was scheduled!
- I did not receive a mail notification that my data is ready for retrieval! Has my request gone lost
- I got an email that says my staging request has failed! What happened
- I got an email that says my staging request was only partially successful! What's going on
- Oops! I made a mistake! How can I stop a request
- My files only contain some error message instead of data
- My data files are corrupted / I cannot unpack my data
- My downloads fail with error "All Ready slots are taken and Ready Thread Queue is full"
- My downloads don't start / time out
- Http downloads randomly fail with "503 Service Temporarily Unavailable"
- When selecting a project it fails with "401 - No permission -- see authorization schemes"
I did not receive a mail notification that my request was scheduled!
If the LTA catalog or StageIT did not show any error when you submitted your request, then it is safe to assume that your request was registered in our staging system. Usually, you should get a notification mail within a few minutes. If you did not receive the notification within an hour of submission and/or your staging request has gone to error from the StageIT view, then our staging service may be down. Note that your request is not lost in this case and will be picked up after the service is back online. Staging requests can be retried in StageIT if they were generated. In urgent cases, if your staging requests are not showing up on StageIT or if you are not sure that something went wrong while submitting your request, please contact the ASTRON SDC helpdesk.
I did not receive a mail notification that my data is ready for retrieval! Has my request gone lost?
After you got a notification that your request was scheduled, it is in our database and there's hardly a possibility that it got lost. Staging requests can take up to a day or two, but will finish a lot sooner in most cases. This depends on your request's size, but also on how busy the storage systems are from other user's requests at that moment. Sometimes, the LTA storage systems are down for maintenance and this can delay the whole procedure. You can check for downtimes here.
It is not alarming when your request did not finish in 24 hours, even when your last request finished within 10 minutes. In urgent cases or if you did not receive a notification after 48 hours, please contact the ASTRON SDC helpdesk.
Sometimes a staging request also fails because the data that were staged are located at different storage sites. It is recommended to check where the data is stored (by hovering over the checkbox for the file and checking which acronym is in the URI: psnc = Poznan, Sara/surf = Amsterdam, FZJ = Juelich), and requesting SAS IDs/files from the same site per submission.
I got an email that says my staging request has failed! What happened?
This means that the storage backend could not fulfil the request at all. This might mean that the system itself is fine, but none of the files from your request could be staged (e.g. missing files). Check the error message from your mail notification for details, or check your StageIT request and see which files failed and possibly why. The notification can also indicate that there is a general problem with the storage system or with the staging service itself, i.e. something is broken or down for maintenance. We try to detect all temporary issues and only inform users in case that something is wrong with their request itself, but we cannot foresee all eventualities. If you cannot make sense out of the error message, or don't know how to deal with it, please contact the ASTRON SDC helpdesk.
If you used StageIT to submit your request with a list of SURLs, please first check whether you made a mistake in (the formatting of) the list.
Note: We get notified of these issues as well and will usually re-schedule failed requests due to server issues after the problem was solved. So please first check whether you got a 'Data ready for retrieval' notification for the same request id after the error notification. If you did, the problem was already resolved.
I got an email that says my staging request was only partially successful! What's going on?
In general, this means that the SRM system works fine, but there was a problem processing your request. As a result, some of your files could be staged, and some could not. The StageIT request ID page should show a list of which files that could not be prepared for download successfully together with an error message to provide the cause. If the error message says 'Incorrect URL: host does not match', this means that you combined files in a requests that are stored on two different SRM locations (e.g. one file at SURF (Amsterdam) and one file at Juelich). When one SRM location gets the request, it can only stage the local files. So in order to avoid this error, you have to request the files from different locations independently. Other messages should be self-explanatory, e.g. if a file is missing. Most often there is a hiccup in the system, and after retrying through the StageIT webpage works wonders. If you cannot make sense out of the error message, or don't know how to deal with it, please contact the ASTRON SDC helpdesk.
If you used StageIT to submit your request with a list of SURLs, please first check whether you made a mistake in (the formatting of) the list.
How to stop a staging request?
It is possible to "abort" your staging request through StageIT per request ID by clicking the red button ![]() , or by clicking the blue "Abort" on the request ID page.
, or by clicking the blue "Abort" on the request ID page.
My files only contain some error message instead of data
Most errors should result in a 404/50x return code. However, some error messages are still returned as a message. Please read the error message carefully. In many cases, it should give you some indication of what went wrong. If this does not help you, please contact the ASTRON SDC helpdesk or retry after a few hours.
Important: If you use wget with option '-c', please note the following: wget does not check the contents of an existing file, so when restarting wget with option '-c' (continue) to retrieve the failed files, it will append the later data chunk to the existing file that contains the error message (and not the first section of you data). Make sure to delete the existing error files (should be obvious by the small file size) before calling 'wget -ci' again, to avoid corrupted data. If you already ended up with a corrupted file, you have to delete that and re-retrieve the whole file.
My data files are corrupted
Check if the files are much smaller than you expect. Something might have gone wrong with the transfer. Please check the beginning of your files, e.g. with the linux 'head' or 'less' commands. If there is an error message, please refer to the question above. Otherwise, please try to re-retrieve the affected file(s). If this does not help, please contact the ASTRON SDC helpdesk.
My downloads fail with error "All Ready slots are taken and Ready Thread Queue is full"
This usually means the storage backend system is overloaded and you should try again in a few hours.
My downloads don't start / time out
Maybe the SRM system is down for maintenance, please check the LTA portal or the LOFAR Downtimes page. If there is nothing going on, there is probably something wrong with the download service. Please try again a bit later and submit a support request to the ASTRON SDC helpdesk if the issue persists.
When selecting a project it fails with "401 - No permission – see authorization schemes"
This happens when you try to select a project when you were not logged into the LTA. Please first select another tab, e.g. search, then try to select your project again.